人工知能(AI)
-

最新AIツールで夏休みの旅行をラクにする6つのステップ
もうすぐ楽しい夏休み。まだすべて完全自動で、というわけにはいかないが、最近のAIツールを使えば旅行先の決定から航空券やホテルの予約、SNSに投稿するレビューの作成まで、面倒な作業をラクにこなせる。
-

人間よりも優秀な「AIうそ発見器」は社会に何をもたらすか?
ドイツの大学の研究チームが、うそを見抜く能力が人間よりも格段に高いツールを開発した。だが、AIうそ発見器の利用は、人間の行動の基盤となる信頼や社会的な絆を壊す可能性がある。
-

見落とされてきた「耳」、音を学んだロボットはもっと賢くなる
ロボットを訓練するのにはこれまで、主に視覚データが用いられてきた。だが、タスクによっては、聴覚データも含めて訓練に使用すると成功率があがることが分かっている。
-

「皮肉屋」の記者をAIでゲームのキャラにしてもらったら?
ビデオゲームをより没入感のあるものにするため、生成AIを使ってNPC(プレイヤーが操作しないキャラクター)を作成するサイトがある。それを使って同僚に、私自身を反映させたキャラクターを作ってもらった。
-

「生成AI革命3」アーカイブ配信:専門家が語った最新動向
今後、生成AI技術はどのような進歩を遂げるのか? MITテクノロジーレビューが6月26日に開催したイベントのアーカイブ動画を、有料会員限定で特別配信する。
-

息づくキャラクターたち、 生成AI・LLMが切り拓く 「ゲームの新時代」
生成AI技術が、ゲームのキャラクターたちに生命を吹き込もうとしている。台本のないキャラクターたちが生き生きと暮らす新しい世界は、かつてない没入感をプレイヤーにもたらす可能性がある。
-

「生成」ではなく「模倣」、 大手レコード会社提訴で 音楽AIの未来に暗雲
-

見えてきた「生成AIの限界」がアーティストの不安を取り除く
生成AIを使った実験を重ねるにつれて、クリエイティブ分野での限界が明確に理解されるようになってきた。AIとアーティストたちの力関係を変えようとする取り組みもいくつか始まっている。
-

顔から全身へ、英ユニコーンの超リアルなAI生成アバターが進化
英国のユニコーン企業であるシンセシア(Synthesia)が新たなAIアバター技術を年内にリリースする。顔だけでなく手などの体の動きも生成するという。
-

中国テック事情:話題の動画生成AI「Kling」を試してみた
中国のテック企業・快手(クアイショウ)が動画生成モデル「Kling」をリリースし、話題になっている。TikTokなどに投稿するショートクリップの制作方法を一変させるかもしれない。
-

解説:生成AIのハルシネーションはなぜ起きるのか
-

台湾防衛の鍵、高度なドローンに 米シンクタンクが予測
-

テスラを超えろ!日本発の自動運転ベンチャーがLLMを作る理由
「2030年に完全自動運転EVを1万台量産する」という日本発の自動運転スタートアップとして注目されるチューリング。同社の青木俊介CTOが語った、自動運転2.0を実現するテクノロジーとは。
-

AI音声による詐欺防止へ メタ、オーディオ透かしで新技術
詐欺やデマ目的での音声クローンツールの使用が増えている。メタの「AudioSeal」というツールが問題への対処に役立つ可能性がある。
-

AIは「笑い」を取れるか? プロがLLMにネタを書かせた結果
大規模言語モデルはコメディのネタを作るツールとして使えるのだろうか? グーグル・ディープマインドの研究チームは、AIを使ったことのあるプロのコメディアン20人に調査を実施し、現時点での結論を得た。
-
「手術ミスゼロ」監視システムに学ぶ、AI導入の3つの教訓
スタンフォード大教授が開発した手術室用のAI機能付き監視装置は、すでにいくつかの病院で使用されている。手術における安全の確保をうたい文句にするが、本来の目的を果たすことができるのだろうか。
-
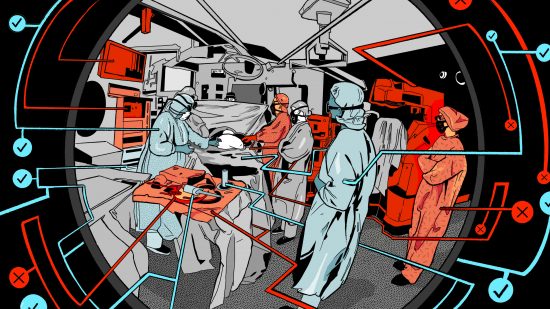
手術室のすべてを記録する 「AIブラックボックス」 医療ミスは撲滅できるか
-

生成AIでも「アップル流」、プライバシー保護で差別化訴え
生成AIブームに出遅れていたアップルがようやく参戦した。新機能「アップル・インテリジェンス」では、プライバシーを保護しながら個人に合ったサービスを提供するという。現時点で分かっている仕組みを解説する。
-

主張:生成AIを使ったプロパガンダ工作、AI企業は実態公表を
-

生成AIはSDGs達成に役立つか? 国連サミットでの学び
-

遭難者のドローン捜索、「勘」から「AI」で早期発見へ
山岳地方などでドローンを使って遭難者を捜索する際、捜索経路はほぼ人間の直感によって計画されている。深層学習AIシステムを使うことで、一分一秒を争う状況でより多くの命を救える可能性がある。
-

「ピザに接着剤がおすすめ」 グーグルの検索AIは なぜ珍回答を返すのか
グーグルの新たなAI検索機能が、誤った情報を表示するケースがソーシャルメディアで指摘されて話題となっている。検索拡張生成(RAG)と呼ばれる手法で幻覚を回避しているはずだが、なぜ問題は起きたのか。
-

中国テック事情:GPT-4oだけじゃない中国語の訓練データ問題
オープンAIの「GPT-4o」の中国語で異常が発生したのは、訓練データの汚染が原因と見られている。背景にあるのは中国のインターネットの構造的な問題だ。
-

フィッシングから脱獄まで、 生成AIで加速する犯罪5つ
生成AIの登場によって、フィッシングや詐欺などの犯罪行為はかつてないほど容易に実行できるようになった。自分の身を守るために知っておきたい、犯罪者のAI利用法を5つ紹介する。
-

eムック Vol.61「検証『生成AI革命』」特集号
MITテクノロジーレビュー[日本版]はeムック Vol.61 / 2024.05をリリースした。今月の特集は「検証「生成AI革命」 破壊と創造は進んだか」。