グーグルが早くも「Gemini 1.5」、最大100万トークン
グーグルが次世代AIモデルの最新版「ジェミニ(Gemini)1.5」を発表した。昨年12月のリリースから早くもアップデートされた新版では、最大100万トークンに対応する。 by James O'Donnell2024.02.17
グーグル・ディープマインド(Google DeepMind)は2月15日、大量の動画、テキスト、画像を処理する機能を強化した、強力な次世代人工知能(AI)モデル「ジェミニ(Gemini)1.5」を発表した。
グーグルが12月に発表したジェミニ1.0からのアップデート版で、サイズと複雑さが異なる「ナノ(Nano)」「プロ(Pro)」「ウルトラ(Ultra)」がある(グーグルは2月7日、多くの製品にジェミニ1.0プロと1.0ウルトラを組み込むことを発表した)。グーグルは現在、一部の開発者および企業顧客向けにジェミニ1.5プロのプレビュー版をリリースしている。グーグルによると、(1.5の3バーションの)中間に位置するスペックのジェミニ1.5プロは、パフォーマンスは以前の最上位モデルであるジェミニ1.0ウルトラに匹敵し、消費するコンピューティング能力は低くなるという(そう、名称がややこしい)。
重要なのは、1.5プロ・モデルは、プロンプト(指示テキスト)の長さを含め、ユーザーからのデータを従来よりはるかに大量に処理できることだ。すべてのAIモデルには処理できるデータ量に上限があるが、新しいジェミニ1.5プロの標準バージョンは、12万8000トークン(トークンはAIモデルが入力を分割する単語、または単語の一部)という多量の入力を処理できる。これはGPT-4の最高バージョン(GPT-4ターボ)に匹敵する性能である。
ただし、一部の開発者グループは最大100万トークンをジェミニ1.5プロに送信できる。およそ1時間の動画、11時間の音声、または70万単語のテキストに相当し、他のモデルが現在実行できないことを可能にする大幅な進歩と言えるだろう。
グーグルが公開した100万トークンのバージョンを使用したデモ動画では、研究チームがAIモデルにアポロ月面着陸ミッションの402ページの記録を与えた。次に、ジェミニにブーツの手描きのスケッチを見せ、その絵が表している瞬間を、(与えられたアポロ計画の)記録の中で特定するように求めた。
そして「これは、ニール・アームストロングが月面に着陸した瞬間です」とジェミニは正しく返答した。さらに「これは1人の人間にとっては小さな一歩だが、人類にとっては大きな飛躍です」とまで付け加えたのだ。
またジェミニは、ユーモアの瞬間を特定することもできた。(先の)アポロ計画の記録でおもしろい瞬間を見つけてほしいと研究チームが求めたところ、ジェミニは宇宙飛行士のマイク・コリンズがアームストロング船長を「皇帝」と呼んだ瞬間をピックアップした(おそらく最良のセリフではないかもしれないが、ポイントは理解できるだろう)。
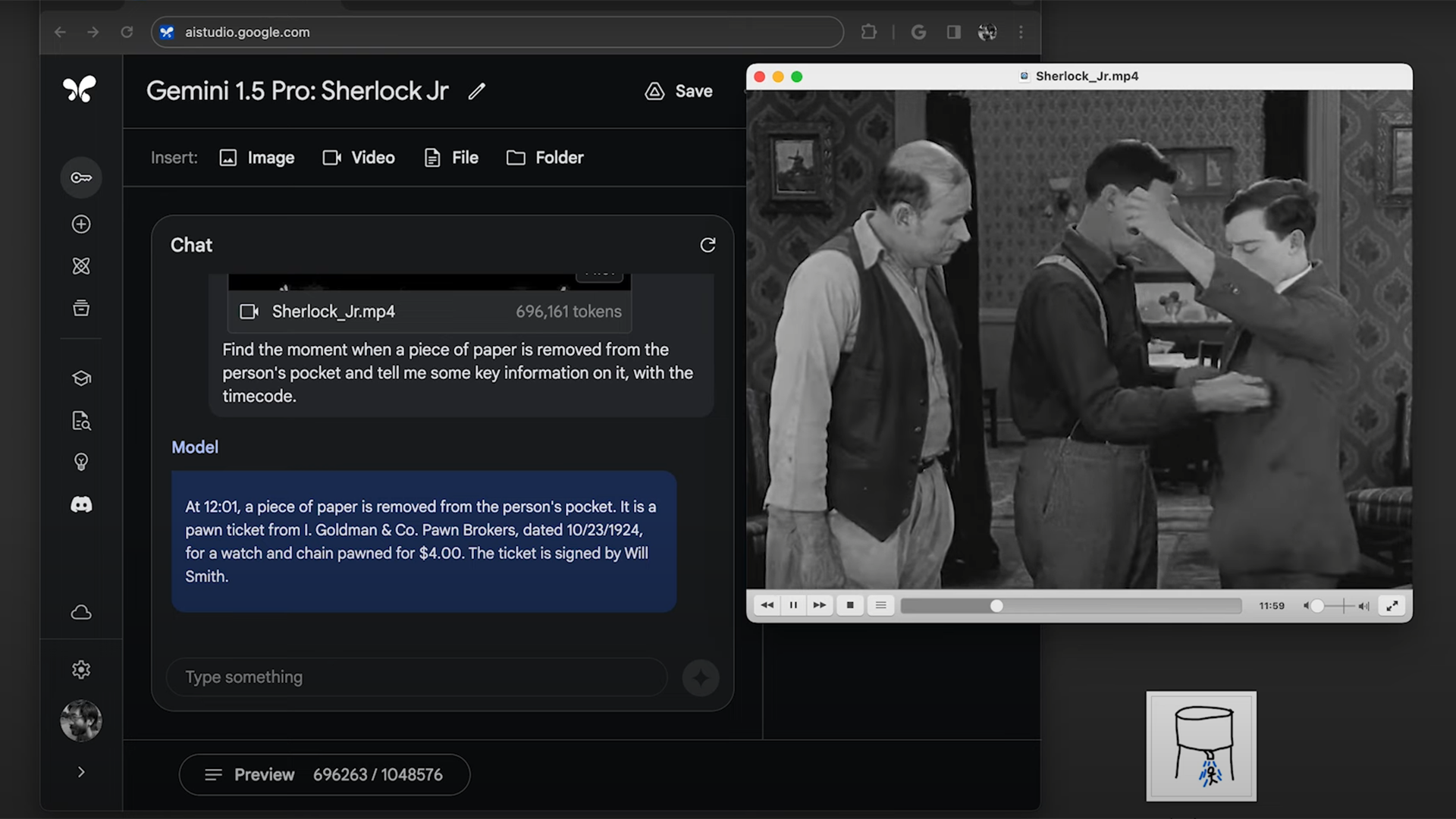
さらに別のデモンストレーションで研究チームは、(喜劇俳優の)バスター・キートンをフィーチャーした44分間の無声映画をアップロードし、映画のある時点で登場人物のポケットから取り出される紙切れに書かれている情報を識別するようジェミニに求めた。1分も経たないうちに、ジェミニはその場面を見つけ、紙に書かれたテキストを正確に思い出した。研究チームはまた、アポロ実験と同様の作業を繰り返し、モデルにスケッチを見せて映画のシーンを見つけるよう求め、ジェミニはそのタスクを完了したのだった。
グーグルによると、ジェミニ1.5プロは、テキスト、コード、画像、オーディオ、ビデオを組み合わせた評価など、大規模言語モデルを開発する際に使用する通常の一連のテストを実施したという。その結果、1.5プロはベンチマークの87%で1.0プロを上回り、すべてのベンチマークでほぼ1.0ウルトラと同等のパフォーマンスを示しながら、使用するコンピューティング能力は低下したことが分かった。
グーグルによれば、より大量の入力を処理できるようになったのは、いわゆる「混合エキスパート(mixture-of-experts)」アーキテクチャの進歩の結果であるいう。この設計を採用したAIは、ニューラル・ネットワークをいくつかのチャンクに分割し、ネットワーク全体を一度に起動するのではなく、当面のタスクに関連する部分のみを起動する(混合エキスパート・アーキテクチャを使用しているのはグーグルだけではない。フランスのAI企業の「ミストラル(Mistral)」もこれを使用したモデルをリリースしており、またGPT-4もこの技術を採用していると噂されている)。
「ある意味では、混合エキスパート・アーキテクチャは私たちの脳とよく似た働きをします。脳は全体が常に活発に動いているわけではありません」とディープマインドの深層学習チームリーダーであるオリオル・ヴィンヤルズは述べている。この区分化によりAIの計算能力が節約され、応答をより速く生成できるようになるのだ。
デモを見たアレン人工知能研究所(Allen Institute for Artificial Intelligence)の元CEOであるオレン・エツィオーニは「異なるモダリティを行き来し、それを検索して理解するために使用するこの種の流動性は、非常に印象的です」と言う。「これは、私が今まで見たことのないものです」。
さまざまなモダリティを超えて動作できるAIは、人間の行動によりよく似たものになるだろう。エツィオーニ元CEOは「人間は本来、マルチモーダルな性質を持っています。なぜなら、私たちは話すこと、書くこと、画像や図を描くことを簡単に切り替えてアイデアを伝えられるからです」と話す。
しかしエツィオーニ元CEOは、この進展を相当重要なものだと考え過ぎないよう警告した。「有名なセリフがあります。AIのデモを決して信用しないこと、というセリフです」 。
まず、デモ動画がどれだけさまざまなタスクを省略しているか、あるいは厳選しているかは明らかではない (確かにグーグルは、動画を高速再生したことを明らかにしなかったとしてジェミニの初期リリースで批判を受けた)。次に、入力された文言がわずかに調整された場合、モデルがデモの一部を再現できない可能性もある。AIモデルは一般的に脆弱だとエツィオーニ元CEOは述べている。
2月15日のジェミニ1.5プロのリリースは、開発者と企業顧客に限定されている。グーグルは、いつ広範にリリースが可能になるかについては明らかにしていない。
- 人気の記事ランキング
-
- Quantum physicists have shrunk and “de-censored” DeepSeek R1 量子技術でDeepSeekを55%小型化、「検閲解除」にも成功
- Promotion Innovators Under 35 Japan Summit 2025 2025年のイノベーターが集結「IU35 Summit」参加者募集
- Google’s new Gemini 3 “vibe-codes” responses and comes with its own agent グーグルが「Gemini 3」発表、質問に応じて回答形式もAIが判断
- How to help friends and family dig out of a conspiracy theory black hole 家族が陰謀論にハマったら: 専門家が語る、 5つの現実的アプローチ
- What is the chance your plane will be hit by space debris? 空からゴミが降ってくる—— 衛星10万基時代のリスク、 航空への影響は?【解説】
- ジェームス・オドネル [James O'Donnell]米国版 AI/ハードウェア担当記者
- 自律自動車や外科用ロボット、チャットボットなどのテクノロジーがもたらす可能性とリスクについて主に取材。MITテクノロジーレビュー入社以前は、PBSの報道番組『フロントライン(FRONTLINE)』の調査報道担当記者。ワシントンポスト、プロパブリカ(ProPublica)、WNYCなどのメディアにも寄稿・出演している。








