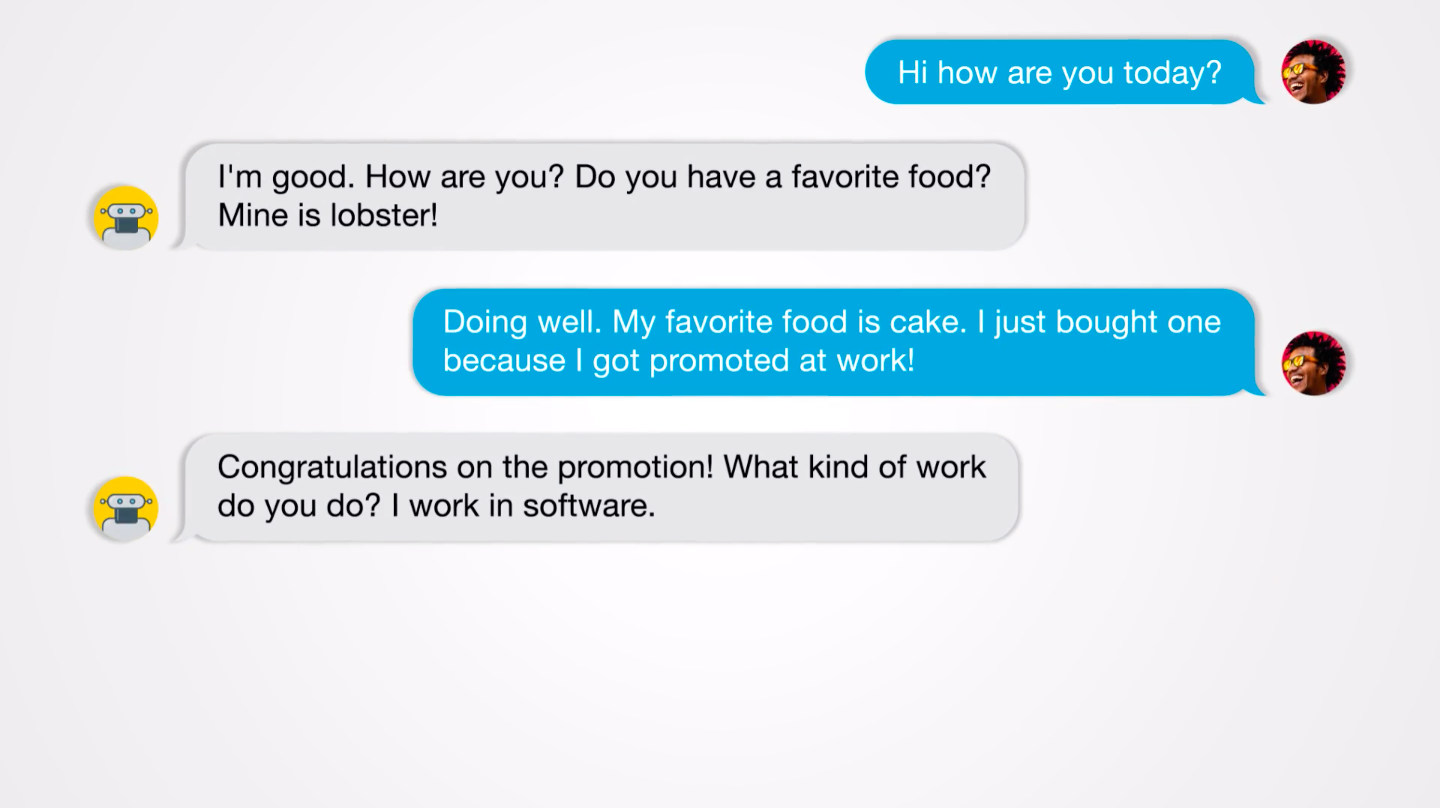
チャットボットやバーチャルアシスタントはこれまで大きな進展を遂げているが、会話はいまだにひどく不得手だ。大部分のボットはタスク指向の色合いが濃く、ユーザーが出した要求に応えるだけだ。こちらが求めているものをまったく理解していないように思えるボットもあり、イライラさせることもしばしばだ。あるいは、人間らしい魅力に欠け、ひどく退屈に感じるボットもある。タイマーをセットするような作業だけを求めているのなら、それでも問題ないだろう。だが、小売から医療、金融サービスまで、あらゆる分野のインターフェイスとしてボットが日常的になるにつれ、その力不足がますます明らかとなっている。
フェイスブックが開発した新型チャットボット「ブレンダー(Blender)」は、ほぼどんな話題でも、人を引きつけるようなおもしろい会話ができるという。ブレンダーは、バーチャルアシスタントが持つ多くの弱点の克服に役立つだけではない。多くの人工知能(AI)研究の原動力となっている偉大な目標に近づいたことを示せる可能性がある。それは、知能を複製するということだ。「対話は、ある種の『AI完全』問題です」と、フェイスブックの研究エンジニアで、今回のプロジェクトのリーダーの一人であるスティーブン・ローラー博士は語る。「対話の問題を解決するにはAIのすべての問題を解決しなくてはなりません。対話の問題が解決できれば、AIのすべての問題が解決したことになります」(同)。
ブレンダーの会話能力は膨大な量の訓練データの賜物だ。まず、掲示板サイト「レディット(Reddit)」で公開されている15億件の会話で訓練を積み、会話中の回答を生成するための土台を築いた。そして、共感力、知識、個性を獲得させるために、それぞれデータを追加して細かい調整をした。共感力をボットに教えるために開発チームは、ある種の感情を含んだ会話のデータセットを用いた。たとえばユーザーが「昇進したよ」と言った場合に、「おめでとう!」と返すといった具合だ。さらに、専門家との情報の詰まった会話を用いて知識を教え込み、特徴的な性格の人同士の会話を用いて個性を吹き込んだ。その結果完成したモデルは、今年1月に発表されたグーグルのチャットボット「ミーナ(Meena)」の3.6倍の規模となった。大きすぎるために単一のデバイスには収まらず、2つのコンピューターチップで稼働させる必要がある。
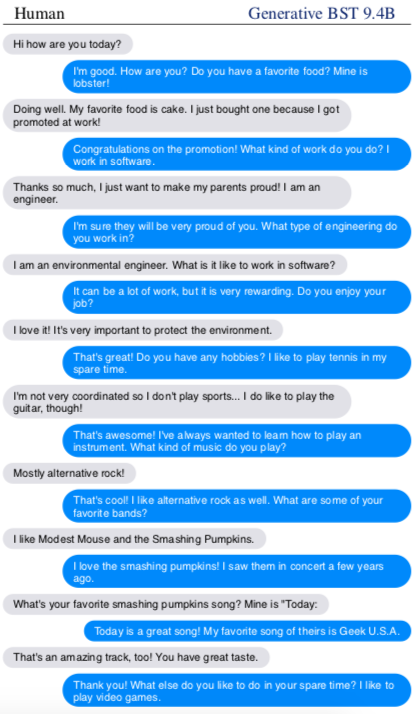
グーグルはミーナを発表した当時、世界最高峰のチャットボットであると宣言した。しかしながら、フェイスブックが実施したテストでは、ミーナよりもブレンダーの方が魅力的である評価した人が75%に上った。より人間らしいと感じた評価者は67%だった。また、ブレンダーは49%の割合で、本物の人間による会話ログよりも人間らしいと感じさせることに成功した。つまり、本物の人間による会話とチャットボットの会話との間に質的な差がないことになる。これらの結果についてグーグルにコメントを求めたが、本記事の締め切りまでに回答は得られなかった。
だが、このようなすばらしい成果がありながら、ブレンダーの能力は人間に遠く及ばない。これまでのところ開発チームは、14回のやりとりで終わる短い会話でしかブレンダーを評価していない。それよりも長く会話を続けた場合、すぐに破綻してしまうだろうと研究者は推定している。「ブレンダーのモデルには、込み入った話をする能力はありません」と、プロジェクトリーダーの一人であるエミリー・ディナンは語る。「数回のやりとりの後には、会話の文脈を忘れてしまうのです」(同)。
ブレンダーはまた、存在しない情報を勝手に作り出したり、事実をでっち上げたりする傾向がある。土台となる深層学習技術が直接もたらす限界だ。結局のところブレンダーは、知識のデータベースではなく、統計的な相関関係に基づいて文を生成しているにすぎない。その結果、たとえば、有名人に関する筋の通った詳細な説明に、まったく虚偽の情報を紐付けることもある。こうした問題を解決するために開発チームは、ブレンダーの回答生成に知識データベースを統合してみることを計画している。

オープンエンドのチャットボット・システムの大きな課題の1つは、有害な内容や偏った意見を言わせないようにすることだ。これらのシステムは最終的にソーシャルメディアで訓練されるため、インターネット上の辛辣な会話の受け売りになりかねない(2016年のマイクロソフトのチャットボット「テイ(Tay)」の例が有名)。開発チームは、ブレンダーの調整に使用した3つのデータセットから有害な文言を除くようにクラウドワーカーに依頼し、この問題に対処しようとした。しかし、レディットのデータに関しては量が多すぎたため、断念したのだ(レディットで多くの時間を過ごした人であれば、その内容が問題となることは理解できるだろう)。
開発チームはまた、チャットボットの回答を二重チェックし、有害な文言を仕分けするなどのより安全な仕組みを取り入れることも考えている。だが研究チームは、そのようなアプローチは包括的にはならないだろうと認める。時として、「そうだ、素晴らしい」といった問題がないように思える文でさえ、人種差別的なコメントへの回答など繊細な文脈では有害な意味になる可能性がある。
フェイスブックのAIチームは長期的に、言葉と同様に視覚的な手がかりに反応できるような、より高度な対話型エージェントの開発にも興味を持っている。たとえば、別のプロジェクトが開発している「Image Chat(イメージ・チャット)」は、ユーザーが送信したような写真について、一定の人格に基づいた繊細な対話が可能だ。
- 人気の記事ランキング
-
- AI companions are the final stage of digital addiction, and lawmakers are taking aim SNS超える中毒性、「AIコンパニオン」に安全対策求める声
- Promotion MITTR Emerging Technology Nite #32 Plus 中国AIをテーマに、MITTR「生成AI革命4」開催のご案内
- Anthropic can now track the bizarre inner workings of a large language model 大規模言語モデルは内部で 何をやっているのか? 覗いて分かった奇妙な回路
- This Texas chemical plant could get its own nuclear reactors 化学工場に小型原子炉、ダウ・ケミカルらが初の敷地内設置を申請
- Tariffs are bad news for batteries トランプ関税で米電池産業に大打撃、主要部品の大半は中国製
- カーレン・ハオ [Karen Hao]米国版 寄稿者
- 受賞歴のあるフリー・ジャーナリスト。人工知能が社会に与える影響について取材している。ウォール・ストリート・ジャーナル紙の海外特派員として中国のテクノロジー業界を担当。2022年4月まではMITテクノロジーレビューのAI担当上級編集者を務めた。










